Using A.I. to Expose Redacted Sensitive Information

While reading Imminent, a newly released book on UAPs by Luis “Lue” Elizondo, I came across something that piqued my curiosity: text redacted by the Department of Defense, left in plain sight. Like anyone intrigued by the unknown, I wondered—what if we could uncover the secrets behind those blacked-out lines? Could these redactions conceal something as significant as a government U.F.O. reverse engineering program? This curiosity led me to an experiment: Could a Large Language Model like ChatGPT infer what had been hidden? The results were more revealing than I anticipated.
The Magic Behind Large Language Models like ChatGPT
Large Language Models (LLMs) like ChatGPT operate by predicting the next word in a sequence based on the context provided by the preceding text. Think of it as a highly advanced autocomplete feature, but instead of just suggesting a single word or phrase, it can generate entire sentences, paragraphs, or even pages of content.
Here's a high-level explanation of how LLMs work:
-
Training on Massive Datasets: LLMs are trained on vast amounts of text data, ranging from books and articles to websites and social media posts. This extensive training helps the model learn the nuances of language, including grammar, syntax, and even cultural references.
-
Understanding Context: When you input text, the model doesn't just look at individual words; it considers the entire context. For instance, if you type "The sun rises in the," the model uses its understanding of language to predict that the next word is likely "east."
-
Generating Predictions: Based on the context, the model generates a range of possible words or phrases that could follow. It then selects the most likely option based on patterns it has learned during training. This process allows it to generate coherent and contextually appropriate text.
-
Iterative Process: The model repeats this prediction process for each new word, continuously building on the context to create more text. This iterative approach is what enables LLMs to produce human-like responses in conversations or generate large blocks of text on specific topics.
-
Flexibility: One of the most powerful aspects of LLMs is their flexibility. They can be fine-tuned for specific tasks, like summarizing articles, answering questions, or even inferring redacted information, as mentioned in the revised post above.
Essentially, Large Language Models (LLMs) function by analyzing vast amounts of text, learning patterns, and using this understanding to predict the most likely sequence of words, resulting in coherent and contextually relevant responses. Most widely-used public models are primarily trained on publicly accessible data.
However, it's important to recognize that countries like China are likely developing their own LLMs. Unlike public models, adversarial nations are not limited to public data; they might also leverage stolen data, such as the information compromised in the Office of Personnel Management data breach, where U.S. Government Security Clearance records were exposed. Additionally, these nations could enhance their models with context gathered through their extensive intelligence networks.
In short, LLMs maintained by nation-states have the potential to be far more accurate and contextually rich than public tools like ChatGPT.
Why Text is Redacted and the Critical Importance of Protecting It
Text is often redacted to protect sensitive information that, if exposed, could have serious consequences. Here are a few common scenarios where redaction is used and why safeguarding this information is crucial:
-
National Security: Governments redact classified information to protect national security. This could include the identities of intelligence agents, details of military operations, or sensitive diplomatic communications. If such information were to be exposed, it could endanger lives, compromise missions, or strain international relations.
-
Legal Proceedings: In court cases, certain details may be redacted to protect the privacy of individuals, particularly in cases involving minors, victims of crime, or confidential informants. Additionally, proprietary business information or trade secrets may be redacted to prevent them from becoming public, which could harm a company’s competitive position.
-
Personal Privacy: Redaction is often used to protect personal privacy, such as in medical records, financial documents, or any other records containing personally identifiable information (PII). Exposing this information could lead to identity theft, financial loss, or other forms of personal harm.
-
Corporate Confidentiality: Businesses often redact information in documents shared externally to protect intellectual property, confidential business strategies, or internal communications. Leaking such information could result in significant financial loss, damage to reputation, or legal repercussions.
-
Investigative Journalism: Journalists may redact information to protect sources, especially in cases where revealing the source's identity could put them at risk. This is essential for maintaining the integrity of the journalistic process and ensuring that sources can come forward with information without fear of retribution.
The importance of protecting redacted information cannot be overstated. If redacted data is revealed, it could lead to catastrophic consequences, including loss of life, compromised security, and severe legal and financial repercussions. Ensuring that redaction is done correctly and thoroughly is a critical component of safeguarding sensitive information in today’s increasingly interconnected world.
Unredacting the Redacted
The first redacted section I encountered was on page four of Imminent. In this section, the exact location of the author’s office had been blacked out by the Department of Defense, as shown below.

Curious to see if I could infer what was hidden, I used ChatGPT’s image analysis feature to analyze the photo and suggest potential locations that might have been redacted.
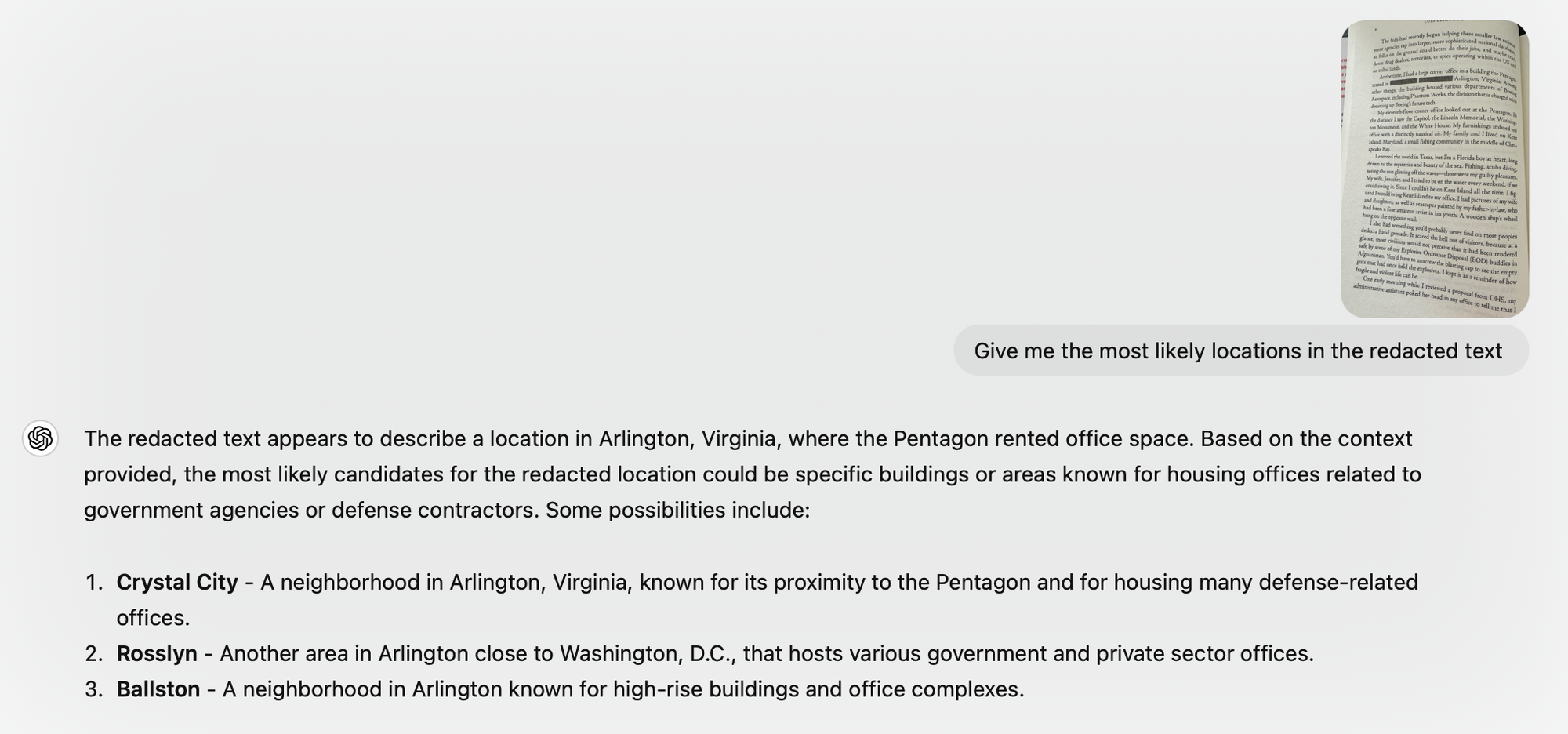
The results were fascinating. ChatGPT’s suggestions appeared plausible given the context, though without a security clearance, I couldn’t verify their accuracy. However, as I continued reading, I stumbled upon something surprising—an apparent oversight by the Department of Defense. On page 12, a location mentioned by ChatGPT appeared unredacted. The familiarity of the words stood out instantly, as I had encountered them just moments before.

This raised a critical question: if a consumer LLM like ChatGPT, without access to classified intelligence, could infer this information so easily and accurately, how much more effective would an adversary's model be, given access to their own intelligence collection apparatus for additional context?
Closing Thoughts
While I’m not an expert in LLMs or AI, it’s clear that these technologies pose a significant risk when it comes to potentially uncovering private or classified information that has been redacted—whether in legal cases, government documents, or other sensitive contexts. This emerging risk requires urgent attention.
As a security researcher, I see this as one of those critical yet often overlooked risks associated with the rapid advancement of new technologies. If your work involves redacting sensitive information, it’s essential to recognize this potential avenue for information leakage. A prudent step could be to redact larger portions of surrounding text, making it more challenging for LLMs to accurately infer the protected details.