
Detectors as Code

Special thanks to Soteria for letting me crosspost work I did while there. Link to the original paper.
The Challenge of Detector Management
Security operations and monitoring teams face a variety of challenges: the rapid evolution of adversarial tradecraft, poor detector documentation, lack of detector version control, poor detection methodology, lack of testing procedures, and change control processes that are slow and time consuming. These issues plague security teams of all sizes, often leading to missed malicious activity, increase in dwell time, and a lower return on investment (ROI) for the overall security program. As a managed detection and response vendor, Soteria recognized that our business would require us to develop new strategies to address these problems in order to provide high quality, actionable detector that scale.
While defining our challenges, we noticed that some of these were similar to the issues faced by software engineers. As a result, software engineers turned to source code management (SCM) tooling, such as GitHub – used in conjunction with modern continuous integration/continuous deployment (CI/CD) pipeline tooling – which allows them to address the issues of version control, testing, and change control. These tools have the added benefit of being inexpensive, well documented and supported, and in many cases have existing integrations into other applications.
Using the methodology defined in this paper, an organization can implement a Detector as Code strategy allowing security operations teams to benefit from the technologies and methodologies built and refined by their engineering counterparts.
Some of the topics discussed in this white paper, such as a complete overview of CI/CD pipelines and other DevOps concepts, are offered only as a brief overview for those unfamiliar with those concepts.
Detectors as Code
Detectors as Code in Context
Software engineering has developed a methodology for testing code for reliability, changes to input data, stability across different operating systems, and building out effective version control systems. This methodology allows teams to identify and review changes to complex software before deployment. This concept, known as development operations, or DevOps, further innovated these processes by adopting ideas from lean manufacturing which focus on continuous delivery techniques providing a fast, scalable way of delivering updates to their products.
Infrastructure operations management has begun adopting a similar methodology with tools such as Puppet Labs’ Puppet, Microsoft’s Powershell Desired State Configuration, and HashiCorp’s Terraform. The use of these techniques allows modern large technology organizations to scale their infrastructure rapidly enough to handle almost any customer demand.
At Soteria, we have adopted a philosophy to build well-documented, high-quality detections with speed, scale, and accuracy by leveraging a CI/CD pipeline to continuously test our detectors for coverage gaps, reliability, and data quality changes. This enables optimal detector precision and minimizes false negatives.
Throughout this paper we use the terms “detector(s)” and “detection(s).” To provide clarity, we have defined these terms as follows:
-
Detector – The logic used to detect specific patterns, signatures, or anomalous activity within an event. Examples include, but are not limited to: Snort rules, EDR rules, SIEM rules, or Bro plugins.
-
Detection – The event(s) that match the logic criteria set forth in a detector for the purpose of review and/or notification for a party.
The Value of CI/CD
Continuous Integration (CI) is a practice where software engineers merge their changes as often as possible. These changes are then validated by creating a build and running automated tests against that build. CI typically places an emphasis on testing automation to verify that the application functions as expected whenever new commits are integrated into the main branch of an SCM repository.
Continuous Deployment (CD) is an extension of CI in which an organization ensures that they can release new changes quickly and in an automated fashion.
From a security perspective, detection engineers often need to make adjustments to the detectors within their environment. By following the CI philosophy, detection engineers can deploy updates to detectors, which are then run through automated tests to verify the fidelity and resiliency of a rule.
Using the CD philosophy, if all of the automated tests pass, the detection deployment process can be automated to push out the new detectors to all platforms. This methodology allows the detection engineers to focus more of their time on building and tuning detectors and reduces the time needed to manually test and deploy them, while simultaneously increasing the fidelity of the detectors themselves.
Benefits of Detectors as Code
Change Control
Responding to alerts generated by an organization’s monitoring technology is a core job function of a security team. Failures to identify malicious activity, known as “false negatives,” can have large operational, financial, or public relations consequences for the organization. With this in mind, it becomes extremely important to implement a well-documented change control process to ensure all changes to detectors are reviewed, documented, and tracked. Typical change control strategies are often slow, time consuming, and difficult (or in some cases impossible) to track after long periods of time due to clutter and lack of good change control tools.
By adopting a Detectors as Code strategy, change control is built in as a core feature. Through the use of SCM tools, security professionals have the ability to easily see all changes to a specific detector for its entire life cycle. This makes it easy for a detection engineer to tune detectors, quickly assess changes in existing detectors, and ensure that all new detectors are reviewed and approved before being pushed into production.
Testing Prior to Deployment
To ensure a detector is functioning properly, it should be thoroughly tested prior to being deployed. Although open source red teaming frameworks can support automation, and commercial breach and attack simulation can make testing easier, it is challenging to configure and perform these tests in an automated and reliable manner. They frequently require dedicated infrastructure and are often mapped to frameworks such as Mitre ATT&CK, which may not cover the use case that needs to be tested.
Through the use of a CI/CD pipeline, customized detection tests can be built to ensure that the detector works as intended. Once this test is built and the outcome is recorded, any future changes made to tune a detector can then be re-tested to ensure the detector has not been overly tuned, causing false negatives.
Version Control
Version control is a process that describes tracking changes to an individual entity or group of related entities. This allows an organization to quickly and easily recall specific versions of the entity at a later date.
Version controlling is extremely important when developing and modifying detectors, as it allows for easy reversion to prior states in the event flaws in the detection logic are discovered. If a detector is discovered to have a flaw long after being tuned, traditional configuration backups may no longer exist. The situation worsens if the responsible detection engineer no longer remembers the original state of the detector or is no longer employed with the company. Proper version control can remediate this issue by maintaining a history of every change made, by which user, and at what time. This allows detection engineers to pinpoint when a detector was changed and notify other teams as needed to perform historical analysis to identify any false negatives that may have happened in that timeframe.
Collaboration
As adversary tactics, techniques, and procedures evolve to evade defenders, it is important to keep your detectors up-to-date. By storing detectors in an SCM platform such as Github or Gitlab, members of the security team can easily collaborate to keep detectors up-to-date.
For example, suppose an adversary group modifies a family of malware to implement a different delivery method in an effort to evade defenders. Because detectors are stored in an SCM Platform, detection engineers can quickly determine whether the existing detector would still be functional or whether it needs to be improved. If it is determined that it needs to be improved, team members have the ability to create a new branch and submit detector improvements that can then be reviewed and discussed within the team.
Soteria has also found that the Detectors as Code method is an excellent avenue of training new security analysts. New analysts have the ability to see how a detector’s logic works, deepening their understanding of the attack. In addition, full contextual information is provided, thanks to the corresponding issue that is created describing the behavior and technique used. By helping analysts understand why and how something is being detected, the time needed for the analyst to investigate the issue is greatly reduced.
Implementation
Process Overview
The image below illustrates our pipeline implementation. Each step serves a specific function that improves our ability to create and maintain high quality detections. As a detector flows through each stage of the pipeline, it is improved upon and further vetted, ensuring the detector is able to identify and alert on what it is looking for.
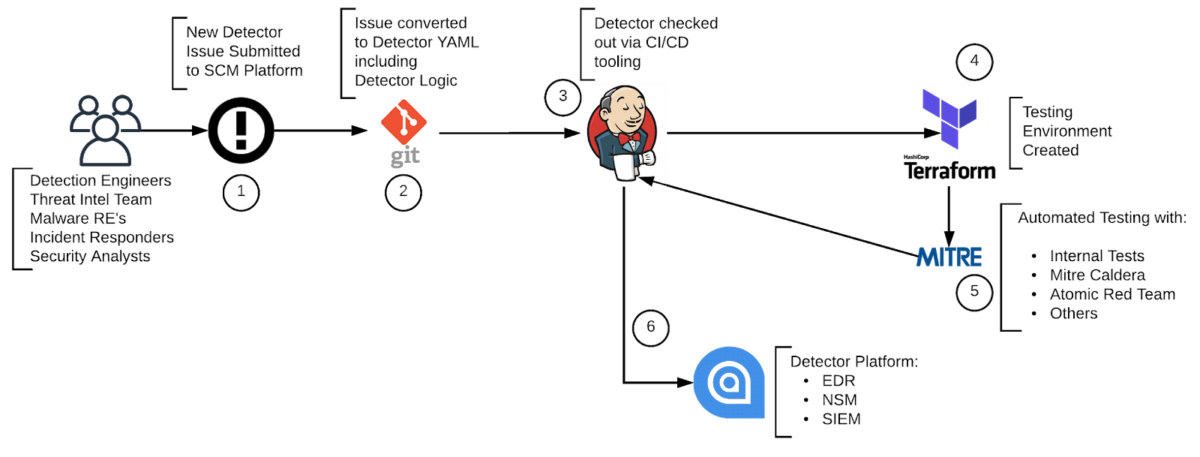
Figure 1: Sample Pipeline
Phase 1: Submitting a New Detector Issue
One of the most important steps into adopting a Detectors as Code strategy is to establish a pipeline that allows members of an organization to submit requests for new detectors. Contributors should be able to submit detection ideas through the new issue or feature request functionality built into the SCM platform. Templates should be created to ensure all data needed by a detection engineer is entered, and labels or tags can be used to help determine priority and associated frameworks. Additionally, detection engineers should set up detector sprints to track performance and guide the team on which detector issues should be prioritized and completed over a given timeframe.
New Detection Coverage Issue Requests
When building a new detector, it is important to document why it is needed and describe the threat model for the detector. This serves dual purposes. First, it allows the detection engineers to build a new detector if they are not familiar with the behavior, technique, or activity in question. Second, it ensures that future analysts understand why a detection exists, what the detector is looking for, and how it applies to their organization.
Organization-specific details should be included, such as applicable frameworks for the detection, whether there are existing automated tests for the new detection request, notes that may help the detection engineer build a more resilient detector, and references (if they exist) to the activity in question.
New issue requests should avoid specifying which detection platform(s) to use or where the detection should be deployed, as these decisions should belong to the detection engineer.
Determining Access Requirements
Typically, organizations go one of two ways when determining who is able to submit new detection issue requests, with the decision resting on organization size and the maturity level of the teams in question.
For organizations that have mature security programs with dedicated penetration testers, malware reverse engineers, and threat intelligence groups, it is preferable to limit the scope of users who can submit new detection coverage requests to the security team. While not always the case, often personnel within infrastructure operations can lack the context of the “what” and “why” of detection, as this is not one of their primarily job responsibilities.
Alternatively, organizations with smaller security teams may have a more open policy on who can submit new detection coverage requests, allowing anyone from within IT or even from non-technical teams to submit. This can be valuable for building a security culture; however, as an organization matures, this can lead to a higher signal-to-noise ratio in terms of the quality of detections and can limit its ability to scale, as non-security teams can often lack the context of what is attempting to be detected.
At Soteria, any member of our team is capable of submitting requests. Red teamers often identify interesting or novel techniques that we feel should be detected, while incident responders and security advisors often contribute ideas based on events they encounter in the field.
Example Issue
Below is a sample new detector request issue that we at Soteria have created in the past. The intent is to detect the use of the Windows binary, mshta.exe, attempting to reach out to a URL. As you can see in the diagram below, the issue template gives us a lot of details including:
- Why it should be detected
- Any pre-built automated tests
- Labels to quickly see what operating systems are impacted and which frameworks it maps to
- Milestones to help prioritize detectors being built as well as to track our progress in building those detectors
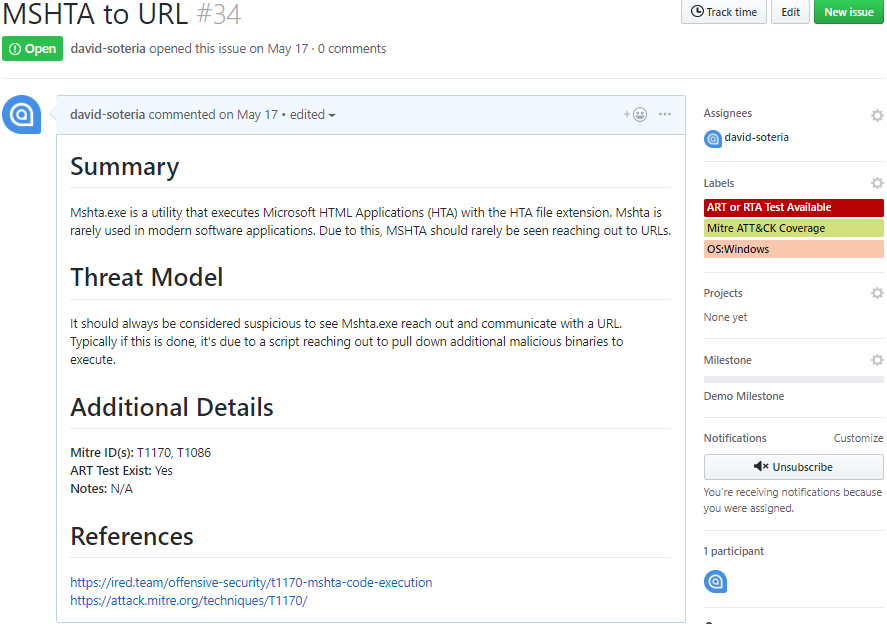
Figure 2: Sample New Detector Issue
Phase 2: Detector Development
Prior to building new detections, the detection engineer should create a template to be used in building out the detector itself. This template should be written in a format that is easy to parse programmatically and readable by humans, such as YAML/TOML.
At a minimum, this template should include the following:
-
Universally Unique Identifier (UUID): Needed to ensure a detector is not created with an overlapping name for a separate detection platform.
-
Detector Name/ID: Provides a field to identify and track the detectors themselves and allow for easier human collaboration.
-
Detection Status: This field serves as a way for automation to track how to deploy a detector. For example, if a detector is listed as “active” it will be deployed to all production platforms. If disabled, it will be removed from those platforms.
-
Detection Logic: This allows the CD tooling to deploy the detection logic to the detection platform in an automated fashion.
After this template has been created, the detector logic should be identified. This may mean doing some localized testing in a testing environment to get the initial detector logic.
Below is an example of a finalized template:
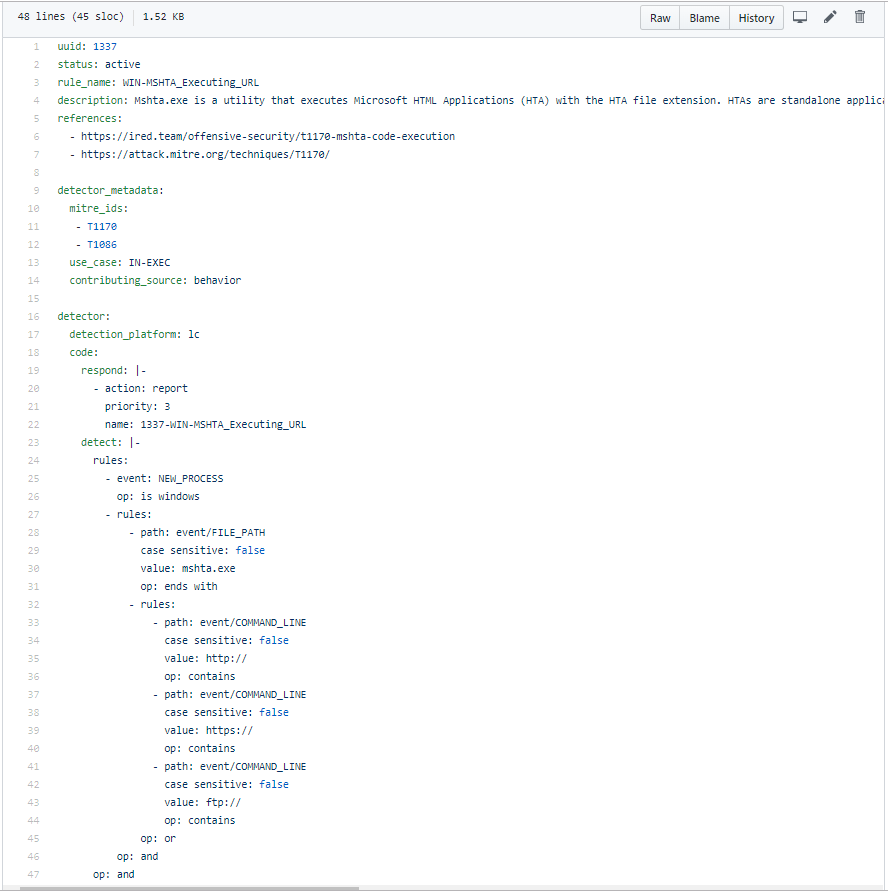
Figure 3: Sample YAML Detector File
Using the data from the YAML configuration file above, we can map and integrate metadata into other internal Soteria tools, such as heat maps aligned with Mitre’s ATT&CK, to help track coverage gaps. Additionally, at the bottom of the YAML file is the detector logic for the LimaCharlie Endpoint Detection and Response platform that we can easily extract and deploy in a programmatic fashion across all of our client networks.
Phase 3: Testing
In this phase, we build tests that will run against the new detector. Once these tests are built, they are integrated into the CI/CD pipeline. Each time a detector is merged into the staging branch, it is executed against the applicable tests. Once these tests complete, peer review is performed to verify whether the detector is accurately identifying the activity described in the issue created in Phase 1 and that all accompanying supporting documentation and configurations are in place.
Building the Tests
We cannot overstate the importance of this step: Poor testing can result in deploying detectors with a high number of false negatives or false positives, a large performance impact that causes service degradation or fragile detections that can be easily evaded or bypassed. We recommend that detection engineers practice modern software testing techniques.
Consider whether the detection logic detects the intended behavior. Through the use of tcpreplay, adversary emulation frameworks, and custom tests, detection engineers should be able to build and deploy tests for the detection logic. Some examples include:
- Read an offline packet capture with your Network Intrusion Detection System (NIDS) to test the new rule logic.
- If your NIDS cannot read PCAPs offline, tools such as tcpreplay can be used.
- Use adversary emulation frameworks that execute the intended behavior to determine whether the detector or log generation is working as intended.
In instances where new adversary techniques are not publicly documented, a test is not offered in existing adversary emulation frameworks, or a packet capture is not available, a custom test may need to be built. Fortunately, this is easier than it may seem. This can be accomplished by generating PCAP files through the use of tools like scapy, and endpoint monitoring tests can be generated through the use of BASH/Powershell scripts or by replaying logs with tools such as log-replay.
Determine whether the detection is resilient to common adversary evasion techniques. It is important to build tests to ensure that the rule’s logic cannot be bypassed easily. Some ways this can be tested include the following:
- Add tests that change the spacing of the indicator.
- Add tests that change the casing of the indicator.
- Add tests that add characters that are ignored by the process executing the behavior in question.
- Add tests that change the file paths in the event system binaries are moved or copied to other directories.
- Modify packet captures to split the intended behavior over multiple packets.
- Unit testing: Does it detect the behavior it is intended to detect?
- Load testing: After being deployed, does the detector negatively impact the detection platforms performance to an unacceptable level?
While building tests can be time consuming, it ensures that all detectors are resilient to evasion and that all future detector tunings preserve that resiliency in an automated fashion. Additionally, most detection tests should be reusable and require only minor tweaks. This means that as more are made, the time required to build new tests is typically reduced.
When building tests, attempt to identify ways to evade your new detectors logic. Let’s take a look at Endgame’s Red Team Automation test for MSHTA files:
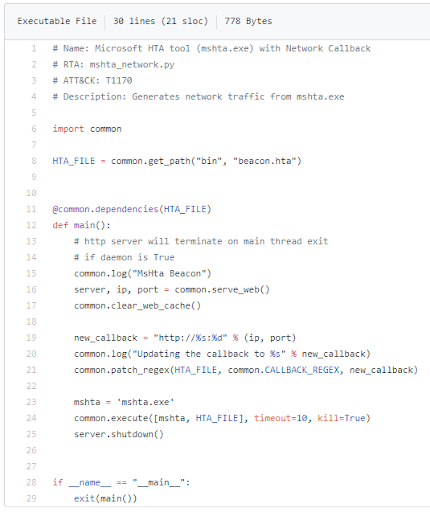
Figure 4: Sample Endgame Red Team Automation test
The code above pulls a sample MSHTA file and hosts it on a simple python web server while telling the system running the Red Team Automation agent to run the command: mshta http://ip:port/hta_file.hta
After the test is executed, you can check to see if the detector triggered on this command. If so, the first test passed. However, if you were not able to detect it, you now know that the detector itself needs to be re-worked in a way so that it will in the future.
Once you have the basic logic down for the detector, attempt to find ways to bypass it. As you can see in the test above, it is testing only urls starting with HTTP. What happens if the url specified by the adversary is HTTPS? Or even FTP? Would your detector still work? While many Red Team Automation frameworks tests are great, they do not always contain tests for common evasion techniques, which means you will find yourself frequently modifying the tests themselves or creating the tests on your own.
If your organization has an internal red team, this can be an excellent area for collaboration that will benefit both the red team members (by having them think of common evasion techniques and how they may be detected) and the blue team members (by helping them learn about evasion techniques from the red teamers that they may not have known about or thought about on their own).
Phase 4: Automated Deployment to Production and Monitoring of the Detector
Once the development branch has been merged into the master branch, the CI/CD tooling reads through the detector configuration. If the detector status is set to active, the CD tooling attempts to deploy the rule logic to the detection platform listed in the configuration file.
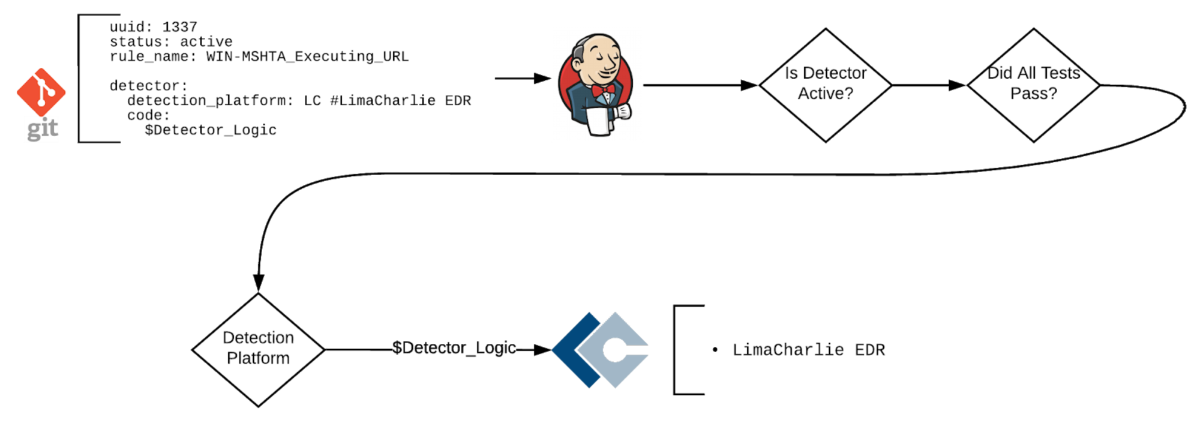
Figure 5: Deployment Example
While much of modern security tooling has centralized management consoles, there are often business cases or architectural reasons that require multiple instances of a detection platform that a detector would need to be pushed to. This is another area in which an automated deployment methodology and technology can increase overall security operations efficiency by reducing the time needed to deploy organization-wide.
It is also important to note that the deployment of new detectors should be monitored to ensure they have an acceptable fidelity. If a detector generates a large number of alerts in a short time after the initial deployment, the detector can be reverted back to a prior state (if due to a tuning change) or easily disabled in an automated fashion. If the massive number of alerts generated are found to be of a high quality, the rule can be easily reenabled and redeployed organization-wide by updating the detector configuration file.
An analytics platform such as a SIEM can be an ideal place to find this information. This is important, as detectors have a lifecycle and will likely require further tuning to prevent false negatives/false positives. As detectors are evaluated and monitored, they will flow through all of the above phases once again.
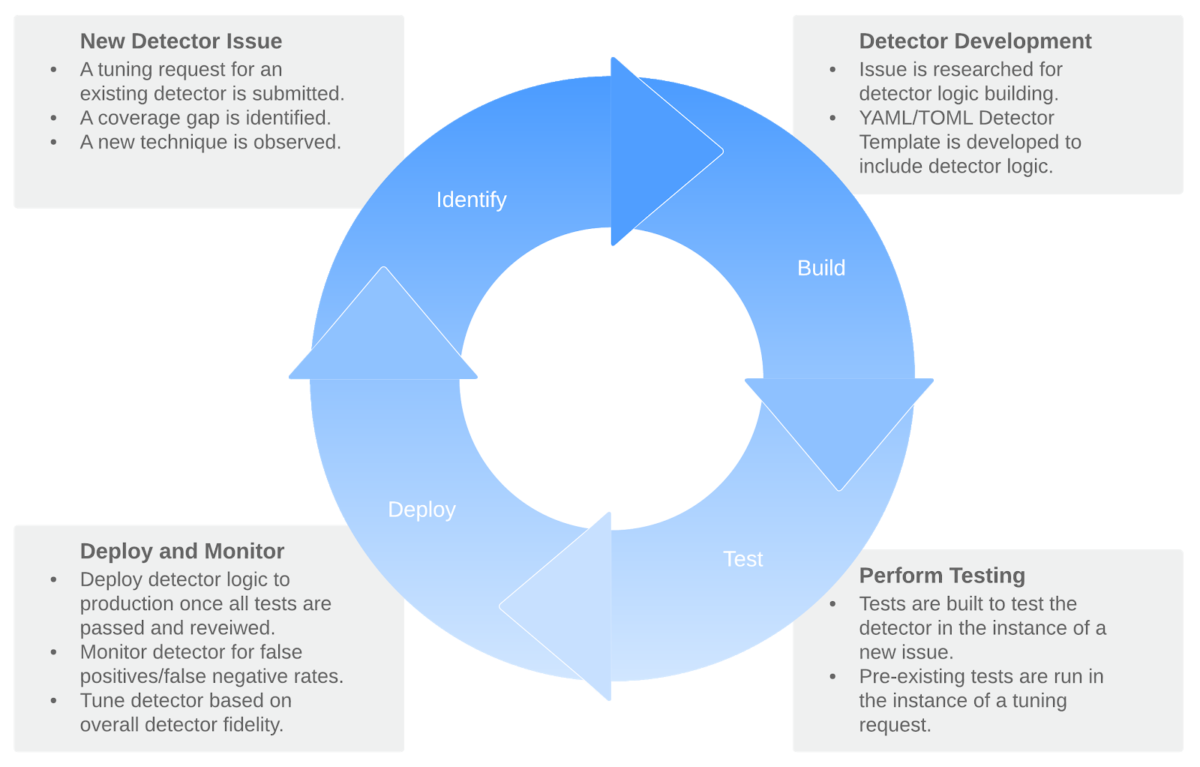
Figure 6: Detector Life Cycle
Conclusion
Modern detection solutions provide security teams with powerful capabilities to analyze massive amounts of data at scale. However, the power afforded by these tools puts the responsibility of tuning and event analysis on the security teams operating the tools. Soteria developed the Detection as Code methodology to allow our MDR team to rapidly prototype, test, and deploy detections in a way that integrates tightly with our technology and scales with our client base. In doing so, our MDR capabilities have matured in many ways, including:
- Facilitating the ability to quickly adapt to rapidly-evolving threats
- Providing assurance that detection logic is sound and not prone to excessive false positives prior to widespread deployment
- Ensuring that security analysts and customers are equipped with comprehensive documentation and playbooks for any alerts that are raised on their watch
- Creating a detailed audit trail, allowing Soteria to quickly analyze and troubleshoot the lifecycle of any detection
Contributors
Thanks to the work of the following individuals from Soteria’s Detection Analysis Response and Triage Team (DART Team) for putting together this paper:
- David Burkett, Detection Engineer, Soteria DART Team
- Brandon Poole, Detection Engineer, Soteria DART Team
Find a technical error in a blog post?
Contact me on BlueSky @signalblur
Already have an account? Sign in
No spam, no sharing to third party. Only you and me.